
目次
概要
Yahoo!検索広告の広告のパフォーマンスレポートのデータ収集に関して以下の2点をお届けします
troccoの場合
troccoの設定
設定手順
- 1.troccoの接続設定でYahooADSAPIを追加
- 2.転送設定
- 3.転送設定の実行
1.troccoの接続設定
接続設定でYahooADSAPIを追加します。
まずは、troccoで接続設定を行います。
サイドメニューの接続設定を選択し、新規作成ボタンを押下し、広告コネクタタブからYahooAdsAPIを選択
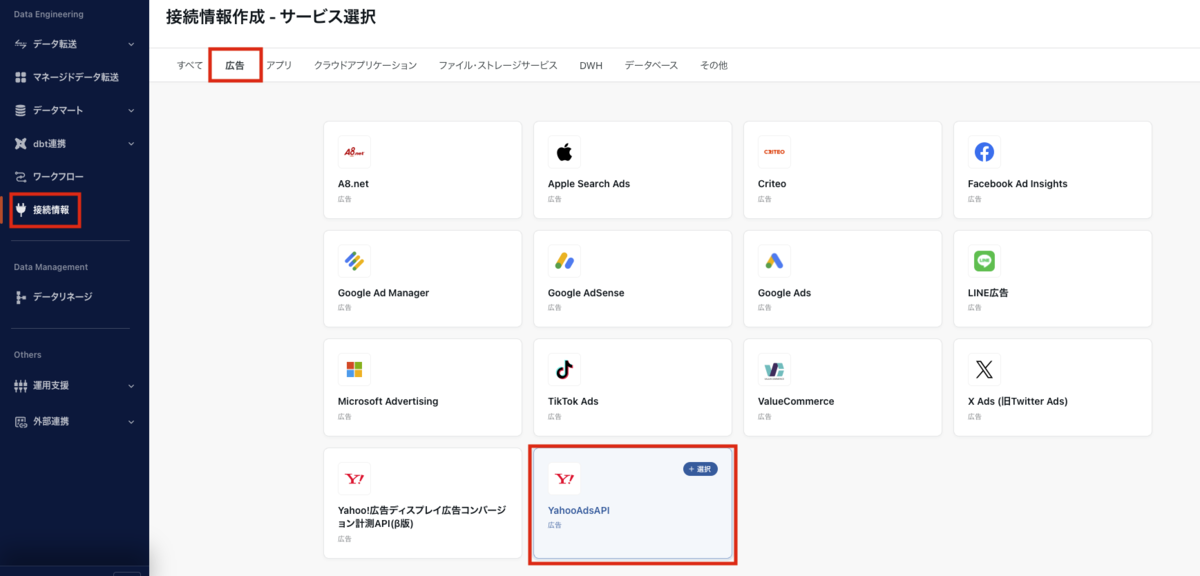
アカウントを認証してOKボタンを押下すれば完了です。
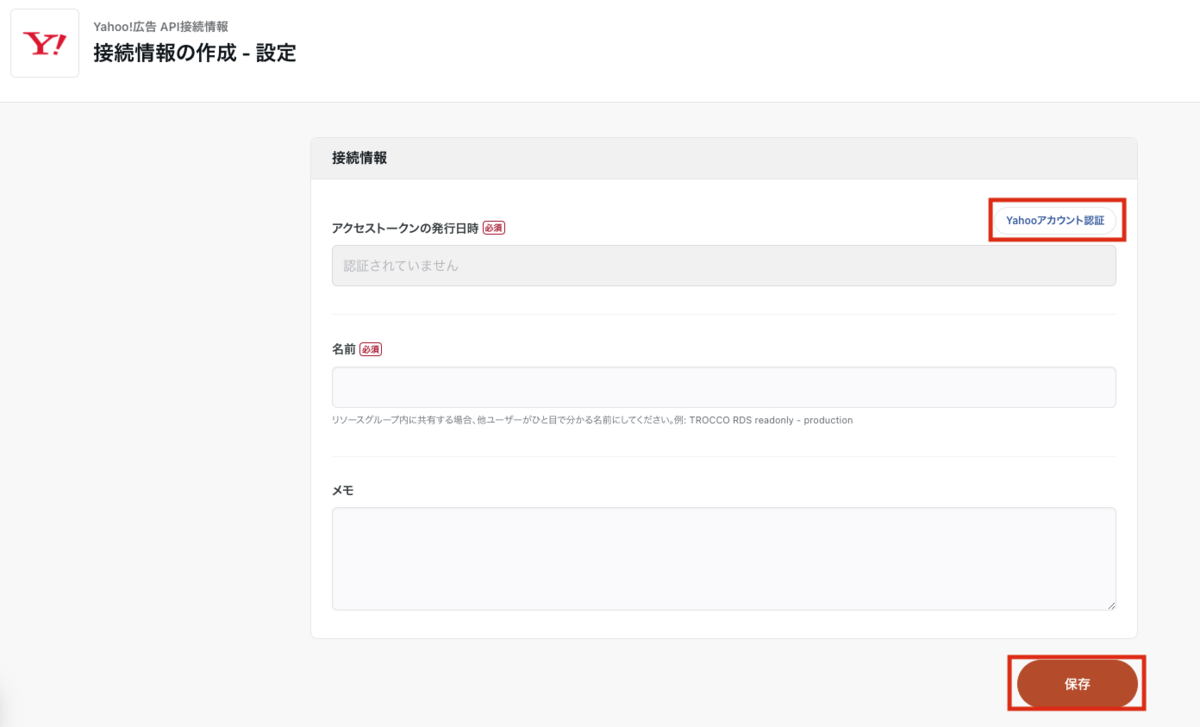
2.転送設定
転送元にYahoo!検索広告を選択し、転送先を設定します。(ここではMySQLを例に設定します)

STEP1から3の設定が必要なので順番に進めます。
STEP1転送元・転送先の設定①概要設定を埋めます
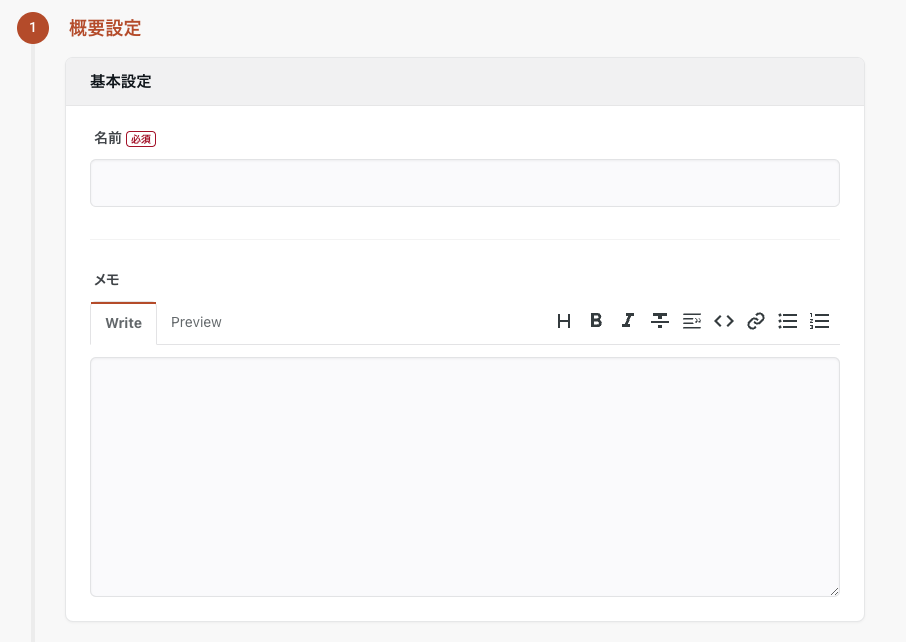
次に、STEP1転送元・転送先の設定②Yahoo!検索広告の設定を埋めていきます。
APIで取得する際に期間指定を行うのでカスタム変数を時刻・日時(キューイング)で設定しましょう
※デイリーで実行したい場合などは1日前に設定すると良いでしょう
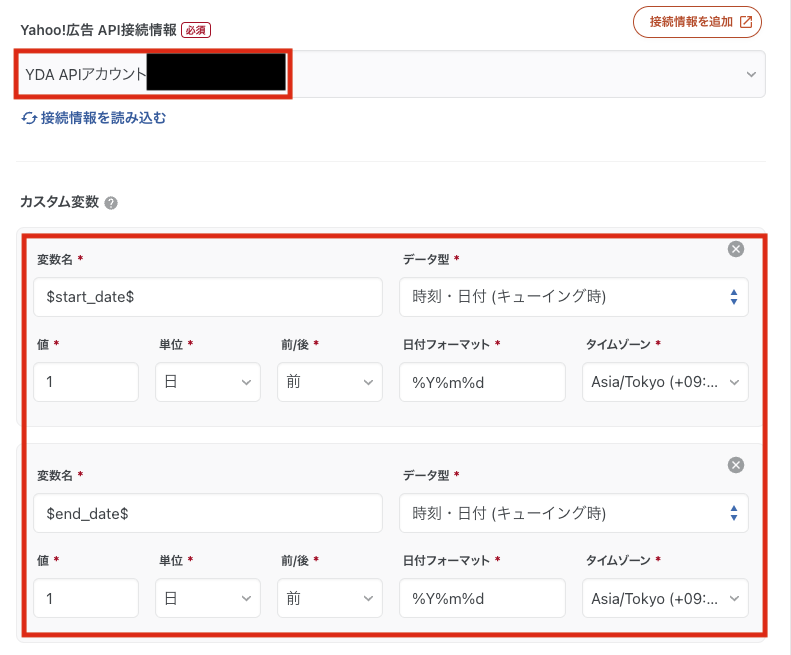
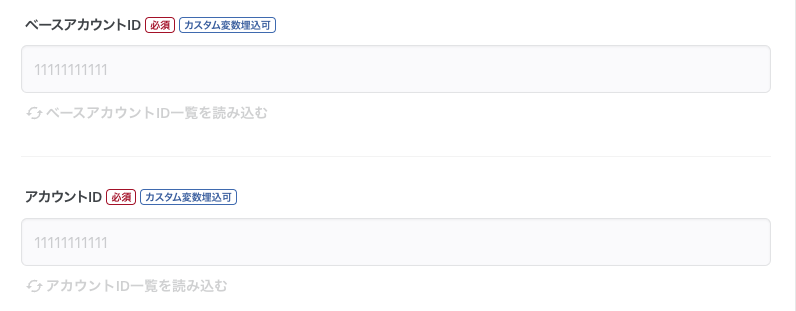
ベースアカウントIDとアカウントIDを設定します
※こちらもカスタム変数化しておくと、1つの転送設定で動的に設定できるようになるので後々便利です。
次に、レポートのテンプレートを設定していきます。 以下のようにサービスとレポート種別を設定した状態で「レポートテンプレート読み込み」リンクを押下すると レポートでよく使う項目が自動で設定されます。データ取得期間に先ほど設定したカスタム変数を使用すると動的に 設定ができるので良いでしょう。
※final_urlなどデフォルトの設定は含まれていないものもあるので注意(テンプレートはあくまでテンプレートなのです。必要なものがなかったら調べて追加しましょう)

次に基本設定へと進み、転送元の情報を設定します。今回はMySQLなので対象のDBとテーブルを指定して、転送時のモードを指定すればOKです。 洗い替えとかでなければINSERTで良いでしょう。
※事前に接続情報の設定が必要です
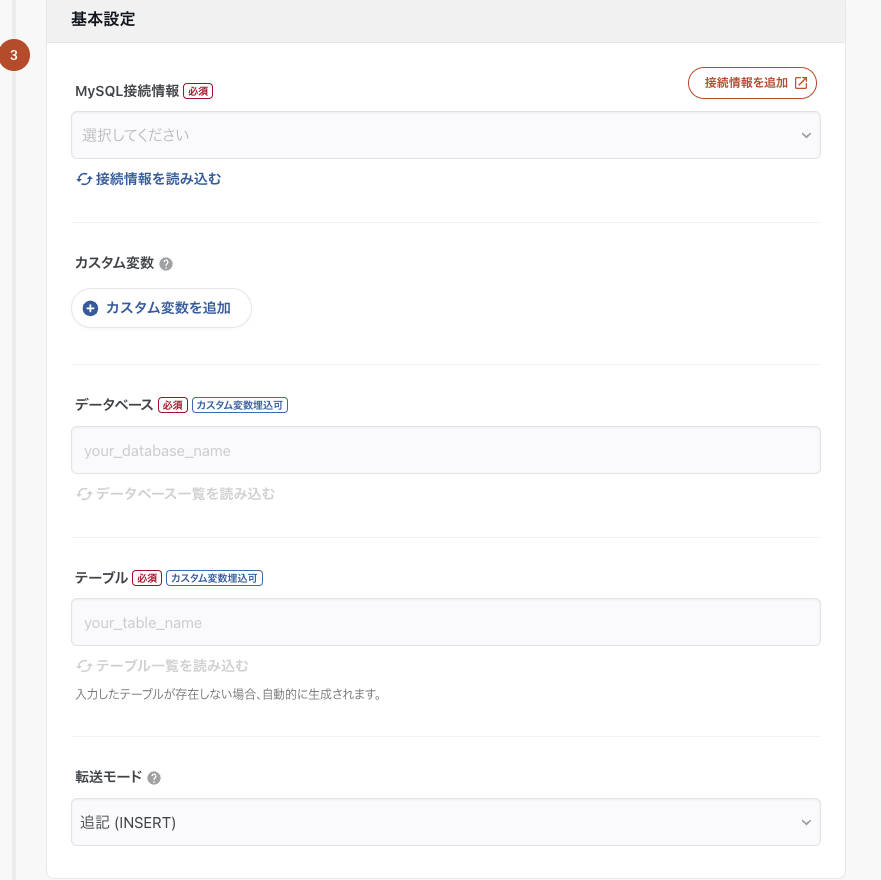
接続確認をして問題なければ、STEP1の設定は完了です。次のSTEPに行きましょう
STEP2,3は長いので雰囲気だけでお送りします。(公式のQA頑張ってーー!!)
STEP2ではSTEP1で設定したレポートテンプレートの項目が転送時のスキーマとして設定されているので、 独自の新規項目追加や型変換などを設定します。元カラム名とDBのテーブルのカラム名は同一でなくても良いので 管理名称に変更しましょう。
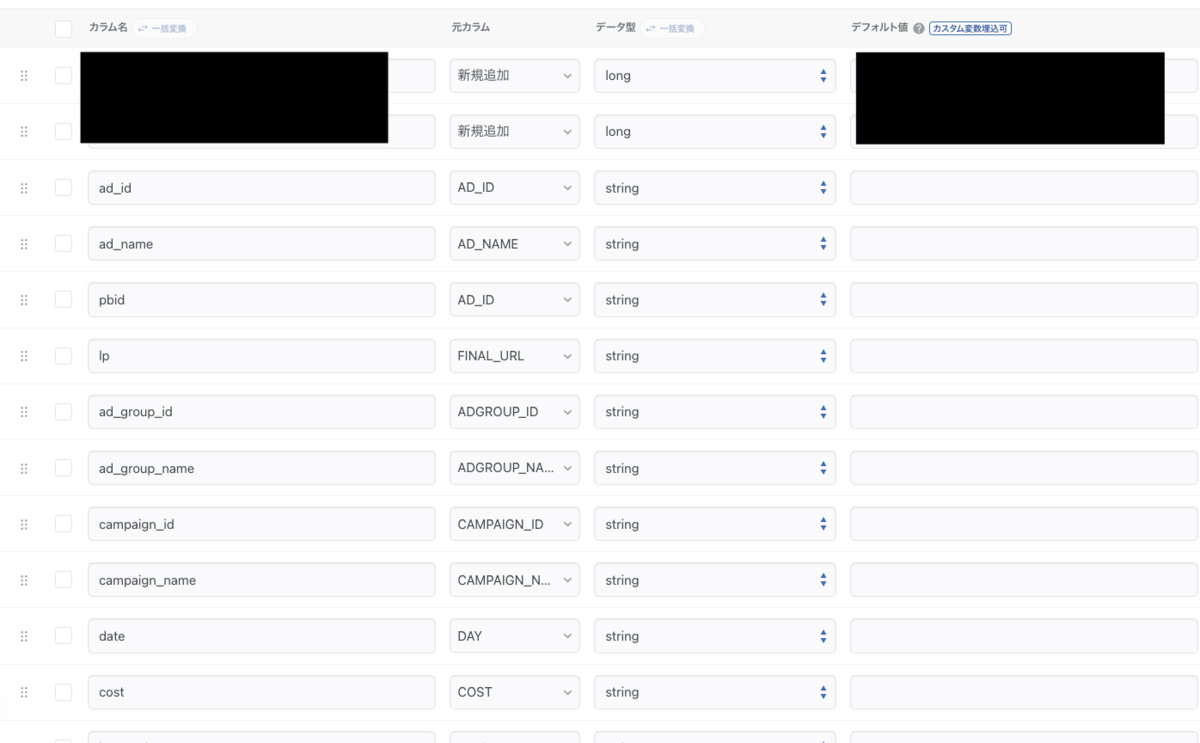
プレビュー機能があるので、データが取得できているかなどを確認し、無事データが取れていればOKです。
下方の確認画面へを押下してSTEP3に進みます。
結構設定多くない?と思ったそこのあなた。もう終わりです。
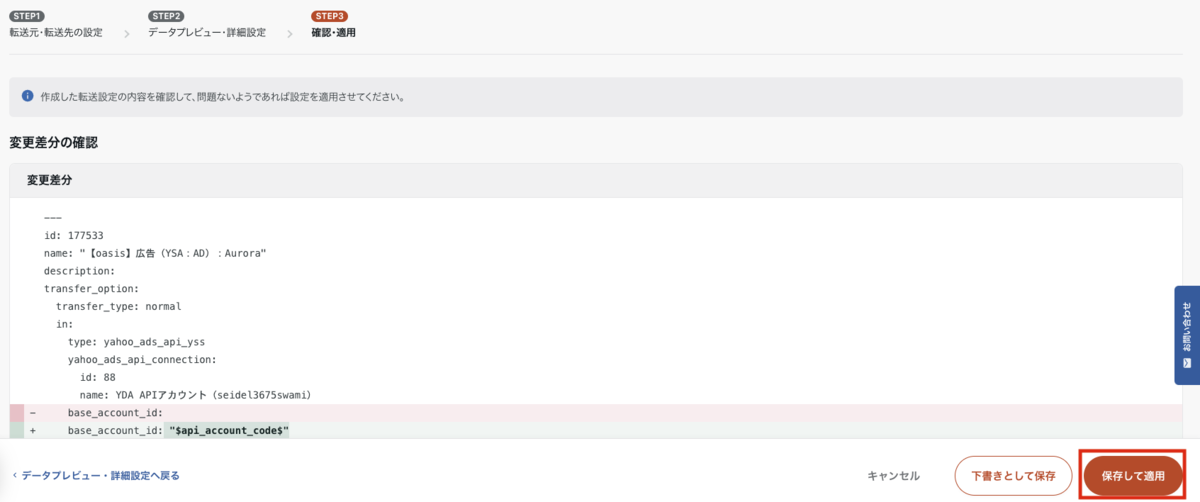
後はSTEP3で保存して適用を押せばOKです
転送設定の実行
設定した転送設定を開いて実行ボタンを押下すれば完了です。
※固定のアカウントを収集するだけで良いようなシーンの場合は転送設定のスケジュールを利用すると便利です。

Pythonでスクラッチで実装した場合
troccoはUI上でぽちぽちしていくだけでデータ連携ができたので最初の設定さえすれば 後は楽でしたね。ここからはPythonでスクラッチで行った場合を書いていきます。
Yahoo!検索広告のAPI仕様のお話になりますが、キャンペーンレポートの取得を例にした場合に、 大きく以下の6STEPに分かれます。
キャンペーンレポート取得
- 1.アクセストークンの取得
- 2.レポート作成
- 3.レポートステータスの取得
- 4.レポートのダウンロード
- 5.レポートファイルの削除
- 6.ダウンロードしたレポートの加工
- 7.収集したデータの蓄積
1.アクセストークンの取得
def get_access_token(client_id, client_secret, refresh_token): token_data = { 'client_id': client_id, 'client_secret': client_secret, 'refresh_token': refresh_token, 'grant_type': 'refresh_token', } response = requests.post(access_token_url, data=token_data) if response.status_code == 200: token_json = response.json() return token_json['access_token'] else: raise Exception(f"Error getting access token: {response.status_code}, {response.text}")
2.レポート作成
def create_report(api_token, base_account_id, account_id, file_name, start_date, end_date, fields, report_type): url = "https://ads-search.yahooapis.jp/api/v14/ReportDefinitionService/add" headers = { "Authorization": f"Bearer {api_token}", "x-z-base-account-id": base_account_id, "Content-Type": "application/json" } payload = { "accountId": account_id, "operand": [ { "accountId": account_id, "dateRange": { "startDate": start_date, "endDate": end_date }, "fields": fields, "reportCompressType": "NONE", "reportDateRangeType": "CUSTOM_DATE", "reportDownloadEncode": "UTF8", "reportDownloadFormat": "CSV", "reportIncludeDeleted": "TRUE", "reportJobStatus": "WAIT", "reportLanguage": "JA", "reportName": file_name, "reportSkipColumnHeader": "FALSE", "reportSkipReportSummary": "TRUE", "reportDecimalPartDisplayType": "FULL_DISPLAY", "reportType": report_type } ] } response = requests.post(url, headers=headers, json=payload) # print(f"Status Code: {response.status_code}") response_data = response.json() # print(response_data) # エラーチェック if response_data.get('errors'): raise Exception("API Error: ", response_data['errors']) # レポートジョブIDの取得 if response_data.get('rval') and response_data['rval']['values'][0].get('reportDefinition'): return response_data['rval']['values'][0]['reportDefinition']['reportJobId'] else: raise Exception("Failed to create report: ", response_data)
3.レポートステータスの取得
レポート作成を行った後で、即座に生成されるわけではないので、レポート生成が完了するまで プーリングを行います。完了すると、ダウンロード用のリンクをresponseとして受け取ることができます。
def get_report_status(api_token, base_account_id, account_id, report_job_id): url = "https://ads-search.yahooapis.jp/api/v14/ReportDefinitionService/get" headers = { "Authorization": f"Bearer {api_token}", "x-z-base-account-id" : base_account_id, "Content-Type": "application/json" } payload = { "accountId": account_id, "reportJobIds": [report_job_id], "reportJobStatuses": ["WAIT","IN_PROGRESS","COMPLETED"], "numberResults": 1, "startIndex": 1 } while True: response = requests.post(url, headers=headers, json=payload) # print(f"Status Code: {response.status_code}") response_data = response.json() # print(response_data) # エラーチェック if response_data.get('errors'): raise Exception("API Error: ", response_data['errors']) # レポートのステータスを確認 if response_data.get('rval') and response_data['rval']['values'][0].get('reportDefinition'): report_status = response_data['rval']['values'][0]['reportDefinition']['reportJobStatus'] if report_status == "COMPLETED": # レポートが完了した場合、ダウンロードURLを返す return response_data['rval']['values'][0]['reportDefinition']['reportJobId'] elif report_status in ["WAIT", "IN_PROGRESS"]: # レポートが完了していない場合、10秒待機して再チェック time.sleep(10) else: raise Exception("Failed to generate report: ", response_data)
4.レポートのダウンロード
レポートの生成が完了したらダウンロードを行います。
def download_report(api_token, base_account_id, account_id, report_job_id, file_name): url = f"https://ads-search.yahooapis.jp/api/v14/ReportDefinitionService/download" headers = { "Authorization": f"Bearer {api_token}", "x-z-base-account-id" : base_account_id, "Content-Type": "application/json" } payload = { "accountId": account_id, "reportJobId": report_job_id } response = requests.post(url, headers=headers, json=payload) # print(f"Status Code: {response.status_code}") with open(file_name, 'wb') as file: file.write(response.content) print(f"Report downloaded as {file_name}")
5.レポートファイルの削除
レポートファイルがYahoo!広告の管理画面上に残ってしまうので、破棄を行います。
def remove_report(api_token, base_account_id, account_id, report_job_id, file_name, start_date, end_date, fields, report_type): url = f"https://ads-search.yahooapis.jp/api/v14/ReportDefinitionService/remove" headers = { "Authorization": f"Bearer {api_token}", "x-z-base-account-id" : base_account_id, "Content-Type": "application/json" } payload = { "accountId": account_id, "operand": [ { "accountId": account_id, "reportJobId": report_job_id } ] } response = requests.post(url, headers=headers, json=payload) # print(f"Status Code: {response.status_code}") response_data = response.json() # エラーチェック if response_data.get('errors'): raise Exception("API Error: ", response_data['errors']) if response_data.get('rval') and response_data['rval']['values'][0]['operationSucceeded']: print(f"Report {report_job_id} successfully removed.") else: raise Exception("Failed to remove report: ", response_data)
6.レポートデータの加工
ダウンロード時に命名したcsvファイルからデータを取り出してDataframeなどに適宜変換します
def load_report_into_dataframe(file_name): df = pd.read_csv(file_name, engine='python', on_bad_lines='skip') return df
メイン処理
一連の処理を流すと以下のような感じになります
def get_monthly_campaign_costs(api_token, base_account_id, account_id, start_date, end_date, file_name): # 参考リンク:https://github.com/yahoojp-marketing/ads-search-api-documents/blob/master/reports/v14/CAMPAIGN.csv fields = [ "MONTH", "ACCOUNT_NAME", "CAMPAIGN_NAME", "COST", "IMPS", "CLICKS", "CLICK_RATE", "AVG_CPC", "CONVERSIONS" ] report_type = "CAMPAIGN" report_job_id = create_report(api_token, base_account_id, account_id, file_name, start_date, end_date, fields, report_type) print(f'report_job_id: {report_job_id}') download_url = get_report_status(api_token, base_account_id, account_id, report_job_id) print(f'download_url: {download_url}') download_report(api_token, base_account_id, account_id, report_job_id, file_name) # ダウンロードしたファイルをデータフレームに変換 df = load_report_into_dataframe(file_name) # レポートを削除 remove_report(api_token, base_account_id, account_id, report_job_id, file_name, start_date, end_date, fields, report_type) return df
7.収集したデータの蓄積
収集したデータを、BigQueryやRDBなどに蓄積します。ここでは長くなるので割愛します。 troccoを使わずに、スクラッチで書いた場合は以下のステップを踏まなくてはならず大変でした。
キャンペーンレポート取得
- 1.アクセストークンの取得
- 2.レポート作成
- 3.レポートステータスの取得
- 4.レポートのダウンロード
- 5.レポートファイルの削除
- 6.ダウンロードしたレポートの加工
- 7.収集したデータの蓄積
ここで気になるのが、あれ?troccoって転送設定の実行だけだったけどどうやってこれ取ってるんだ?ということです。 ということでちょっと裏側を調べてみました。
embulkの処理
troccoはOSSのembulkを使用しています。 なのでコネクタの一部はembulkを使用していると思われます。
※troccoでembulkのプラグインを使用していることを保証するものではありません
embulkのpluginの一覧ページを開いて、該当のプラグインを探します。 plugins.embulk.org
おっ、何かそれっぽいのがありました。

フィーリングでそれっぽい処理を探し当てます github.com
あれれ、何か既視感が。。。。これはやってますね。。。。
スマートなやり方なんかはなくて、どこかの誰かが泥臭い作業を肩代わりしてくれてるんですよね。きっと。

まとめ
はい、ということで今回はYahoo!検索広告のレポートをtroccoを使用した場合とスクラッチで取得した場合で比較しつつ、embulkの処理内容に関しても確認しました。スクラッチ開発により柔軟性は取れるものの、EOLやビジネスドメイン知識などを踏まえるとtroccoのコネクタを使用することで代替できる部分が多いなと改めて思いました。ご参考になれば幸いです。