どうもキュービックのテックリードをやっている尾﨑です。2月10日にデブサミに登壇してきました。
どうもキュービックのテックリードをやっている尾﨑です。2月10日にデブサミに登壇してきました。
アーキテクチャの中のサービスに関して1つ1つ詳細をお話しすることができなかったので、利用技術やハマった点などを交えてご紹介していきたいと思います。
今回はTableau REST APIを使ってスプレッドシート連携を自動化した事例をご紹介します。
ボリュームがあるので、手っ取り早くTableau APIの良し悪しと用法を把握したい方は目次の5以降を参照ください。

1.なぜTableau REST APIでスプシ連携ツールを作ろうと思ったか
キュービックではBIツールとしてTableauを使用しており、収集したデータを加工・集計してビジネスサイドがモニタリングできるようにアウトプットをTableauのワークブック上にビジュアライゼーションしています。TableauにはエクセルやCSVダウンロード機能はあるものの、標準でスプレッドシート連携機能がなかったので、こちらを最小工数で自動化できないか?と考えたのがきっかけでした。
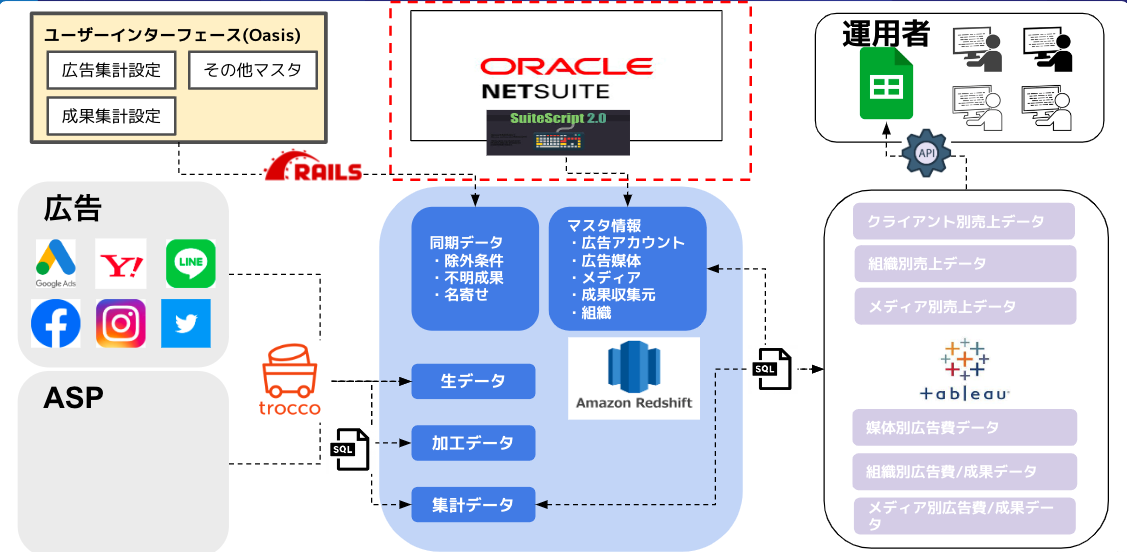
2.スプシ連携ツールの構成
 構成1
構成1
 構成2
構成2
3.スプシ連携ツール作成時に工夫したところ
4.スプシ連携ツールの改善点
- 問題
- スプシのテンプレートに更新があった際にバージョン追随ができない
- 運用者に最新テンプレートに乗り換えてもらう必要がある
- 課題(解決策)
- 移行コストを如何に削減するか?を考慮する方向で検討 (WEBアプリ化はしない)
★5.Tableau REST APIの主要な機能
作成したスプシ連携ツールでは、TableauのView情報を取得(参照)することを目的としているため、
Tableauに対してAPIで登録/更新/削除を実行するようなものは触れません。
今回は1を中心に解説します。
以下のような方向けにできるだけ分かりやすく解説していきます
アクセストークン取得
まずは、個人用アクセストークンを発行し、アクセストークンとsite-idを取得します。
リクエスト情報
| ヘッダー |
設定値 |
| Content-Type |
application/json |
| Accept |
application/json |
1.リクエスト情報のパラメータの設定値に指定した以下の情報を設定してください。
- personalAccessTokenName
- personalAccessTokenSecret
- contentUrl
function getTableauAcccessToken() {
var requestPayload = {
"credentials": {
"personalAccessTokenName": "your Access Key Name",
"personalAccessTokenSecret": "your Access Key",
"site": {
"contentUrl": "your content URL"
}
}
}
var requestHeaders = {
'Content-Type': 'application/json',
'Accept' : 'application/json'
}
var requestOptions = {
'method' : 'post',
'payload' : JSON.stringify(requestPayload),
'headers' : requestHeaders,
}
var requestUrl = 'https://10az.online.tableau.com/api/3.4/auth/signin';
var response = UrlFetchApp.fetch(requestUrl, requestOptions);
var responseCode = response.getResponseCode();
var responseText = response.getContentText();
var result = JSON.parse(responseText)['credentials']
return result;
}
2.APIのresponse結果としてcredentialsを取得します
- リクエストが成功するとsiteのid(site-id)とtoken(アクセストークン)が取得できます
{
"credentials": {
"site": {
"id": "sample",
"contentUrl": "sample"
},
"user": {
"id": "sample"
},
"token": "sample",
"estimatedTimeToExpiration": "270:11:00"
}
}
ワークブック情報取得
次に、Tableauのワークブックの情報を取得します。
リクエスト情報
- ※site-idに関しては「アクセストークン取得」にて取得
| ヘッダー |
設定値 |
| X-Tableau-Auth |
「アクセストークン取得」で取得したアクセストークン |
| Accept |
application/json |
| パラメータ |
概要 /設定値 |
| pageSize |
取得データ件数(defaultは100件) |
1.アクセストークン取得で取得した以下の情報を使用します
- siteのid(siteId)
- token(アクセストークン)
function getWorkBookInfo() {
tokenInfo = getTableauAcccessToken();
var pageNumber = 1;
var requestHeaders = {
'X-Tableau-Auth' : tokenInfo['token'],
'Accept' : 'application/json'
}
var requestOptions = {
"method" : "get",
"headers" : requestHeaders
}
var siteId = tokenInfo['site']['id'];
var requestUrl = `https://10az.online.tableau.com/api/3.17/sites/${siteId}/workbooks?pageSize=1000`;
var response = UrlFetchApp.fetch(requestUrl, requestOptions);
var responseCode = response.getResponseCode();
var responseText = response.getContentText();
var result = JSON.parse(responseText)['workbooks'];
return result;
}
2.APIのresponse結果としてworkbooksを取得します
- リクエストが成功すると以下のような情報が取得できます
{
"pagination": {
"pageNumber": "1",
"pageSize": "100",
"totalAvailable": "304"
},
"workbooks": {
"workbook": [
{
"project": {
"id": "0c5b75e8-8895-4d17-a9fb-f3047a",
"name": "転職"
},
"location": {
"id": "0c5b75e8-8895-4d17-a9fb-f3047a",
"type": "Project",
"name": "転職"
},
"owner": {
"id": "3f5dfad5-1f00-41ed-9eb8-7",
"name": "sample@cuebic.co.jp"//オーナーのメールアドレス
},
"tags": {
},
"dataAccelerationConfig": {
"accelerationEnabled": false
},
"id": "e25e09f0-a2db-49dc-999e-eb6f6",
"name": "分析用",
"description": "",
"contentUrl": "_0",
"webpageUrl": "https://10az.online.tableau.com/#/site/contentUrl/workbooks/1521246",//ワークブックのURL
"showTabs": "true",
"size": "99",
"createdAt": "2019-05-04T04:04:37Z",
"updatedAt": "2021-07-13T05:21:00Z",
"encryptExtracts": "false",
"defaultViewId": "45776cde-f128-442f-92b"
},
]
}
}
3.もし必須情報を取得したい場合は以下をresultの後続処理に追加すると良い感じにデータが取得できます
var kaigyo ="\n";
var workBookInfoArray = [];
workBookInfoArray[0] =[
`ワークブック名${kaigyo}name`,
`ワークブックID${kaigyo}id`,
`ワークブックURL${kaigyo}webpageUrl`,
`プロジェクトID${kaigyo}project:id`,
`プロジェクト名${kaigyo}project:name`,
`オーナーID${kaigyo}owner:id`,
`オーナーメールアドレス${kaigyo}owner:name`
]
var j= 0;
var cnt = 1;
for(i=0; i<result['workbook'].length; i++){
if(!result['workbook'][j]['project']){
j++
continue;
}
workBookInfoArray[cnt]= [
result['workbook'][j]['name'],
result['workbook'][j]['id'],
result['workbook'][j]['webpageUrl'],
result['workbook'][j]['project']['id'],
result['workbook'][j]['project']['name'],
result['workbook'][j]['owner']['id'],
result['workbook'][j]['owner']['name']
]
j++
cnt ++
}
View一覧取得
次に、TableauのワークブックのViewのリストを取得します。
リクエスト情報
- ※site-idに関しては「アクセストークン取得」にて取得
- ※workbook-idに関しては「ワークブック情報取得」にて取得
| ヘッダー |
設定値 |
| X-Tableau-Auth |
「アクセストークン取得」で取得したアクセストークン |
| Accept |
application/json |
| パラメータ |
概要 /設定値 |
| pageSize |
取得データ件数(defaultは100件) |
1.ワークブック情報取得で取得したworkbookのid(workBooksId)を使用してViewの一覧を取得します
function getViewID(name,workBooksId) {
tokenInfo = getTableauAcccessToken();
var requestHeaders = {
'X-Tableau-Auth' : tokenInfo['token'],
'Accept' : 'application/json',
'pageSize' : 1000
}
var requestOptions = {
"method" : "get",
"headers" : requestHeaders
}
var siteId = tokenInfo['site']['id']
var requestUrl = `https://10az.online.tableau.com/api/3.17/sites/${siteId}/workbooks/${workBooksId}/views`;
var response = UrlFetchApp.fetch(requestUrl, requestOptions)
var responseText = response.getContentText()
var result = JSON.parse(responseText)['views'];
return result;
}
2.APIのresponse結果としてviewsを取得します
- リクエストが成功すると以下のような情報が取得できます
- これで取得したいワークブックのIDとView(シート)のIDが取得できました。
{
"views": {
"view": [
{
"tags": {
},
"id": "bb9aeee4-b144-49e3-9e66-2749c9",//ViewのID
"name": "広告アカウント_抽出",//View(ワークブックのシート名)
"contentUrl": "AD/sheets/PBID_",
"createdAt": "2023-02-15T13:09:57Z",
"updatedAt": "2023-02-21T02:41:15Z",
"viewUrlName": "PBID_"
},
]
}
}
View情報取得
これでView情報を取得するのに必要な情報が集まりました。
今度は、TableauのワークブックのViewの詳細情報を取得します。
リクエスト情報
- ※site-idに関しては「アクセストークン取得」にて取得
- ※workbook-idに関しては「ワークブック情報取得」にて取得
- ※view-idに関してはViewsリスト取にて取得
| ヘッダー |
設定値 |
| X-Tableau-Auth |
「アクセストークン取得」で取得したアクセストークン |
| Accept |
application/json |
| パラメータ |
概要 /設定値 |
| vf_ {fieldname} |
vf_{filter_name}の表記でパラムを設定してTableauのView上のフィルターと同等の絞り込みを実現できる |
1.View一覧取得で取得したviewIdを指定してViewの詳細情報を取得します
function getViewinfo() {
var tokenInfo = getTableauAcccessToken();
var requestHeaders = {
'X-Tableau-Auth' : tokenInfo['token'],
'Accept' : 'application/json'
}
var requestOptions = {
"method" : "get",
"headers" : requestHeaders,
"muteHttpExceptions" : true
}
var siteId = tokenInfo['site']['id']
var requestUrl = `https://10az.online.tableau.com/api/3.17/sites/${siteId}/views/${viewId}/data`;
var response = UrlFetchApp.fetch(requestUrl, requestOptions)
var responseText = response.getContentText();
result = Utilities.parseCsv(responseText);
return result;
}
2.APIのresponse結果としてviewの詳細情報を取得します
- リクエストが成功すると以下のようなCSVデータが取得できます
ad_media,Measure Names,Month of day,Year of day,粗利,Measure Values
FB2,imp,August,FY 2020,"115,343","94,140"
FB2,click,August,FY 2020,"115,343","1,480"
FB2,ctr,August,FY 2020,"115,343",0.015721266
FB2,cpc,August,FY 2020,"115,343",85.376351351
FB2,cost,August,FY 2020,"115,343","126,357"
FB2,avg.position,August,FY 2020,"115,343",
FB2,preCV,August,FY 2020,"115,343",219
★7.Tableau REST APIの良かったところ
★8.Tableau REST APIの改善して欲しいところ
- Viewで定義されているフィルター情報の一覧をView毎に取得することができない
- 現在はスプレッドシート上に最大公約数的にフィルターに相当するパラメータを用意しておき、運用者に埋めてもらっている状態
- Tableauで運用者がviewのフォーマットを意図せずに更新するとエラーが起きてしまう可能性があります
- API keyが最大で1年しか持たないところ
- 連続したアクセスが2週間以上ない場合は非有効化されるのでGASでトリガーを設定しています
- アラートを設定したとしてもツール作成者居なくなったら負債化する可能性があります

- CSVでエクスポートしたものとAPIで取得したデータの出力フォーマットが異なる
- CSVでダウンロードしたものはtableau側でよしなにピボットしてくれておりViewに近い形で出力されます
- APIで取得したデータは列が行として認識されるものがあり、個別に整形が必要になります
- エラー内容が不親切
- 「フォーマットが未対応」のような抽象的なエラーのみがエラーメッセージとして返ってきます
- ワークブック上で誰かが編集モードで掴んでいるViewや正式にpublishされていないViewは取得できないことがありました