背景
こんにちは、キュービックでSREをやっているYuhta28です。キュービック内のテック技術について発信します。
弊社では業務で扱うファイルを格納するストレージにGoogeドライブを利用しており、基本的に参照は社内の人のみに限られます。ただ場合によっては社内のファイルを外部の人に見せたり、別サービスから画像ファイルを出力させたいという要件が発生します。
先日GoogleのLooker Studio1に社内で管理している数GBもある大量の画像ファイルを出力したいという要望がありました。直接Google Driveから参照するのではなくS3経由で画像を出力させたいとのことですが、Googleドライブのファイルは定期的に更新されるので更新されるたびに手動でストレージ間同期するのも面倒なので定期実行できる仕組みが必要だと考えました。
今回はRcloneというOSSを使い、GoogleドライブとS3のファイル同期及び実行環境をECS Fargateにすることで定的に自動実行できるようにしましたのでどのように設定したかについて紹介いたします。
対象読者
- クラウドストレージ間のファイル同期方法について検討している
- Rcloneの使い方について知りたい
Rcloneとは
Rcloneはクラウドストレージ上のファイルを管理できるコマンドラインツールです。S3やGoogleドライブなど70以上ものクラウドストレージに対応しており、クラウドストレージとローカル間、クラウドストレージ同士のファイルのコピーや移動、参照コマンドも可能なGo製のOSSとなります。
インストールページを見ても分かる通り幅広い環境で実行できる優れたツールです。
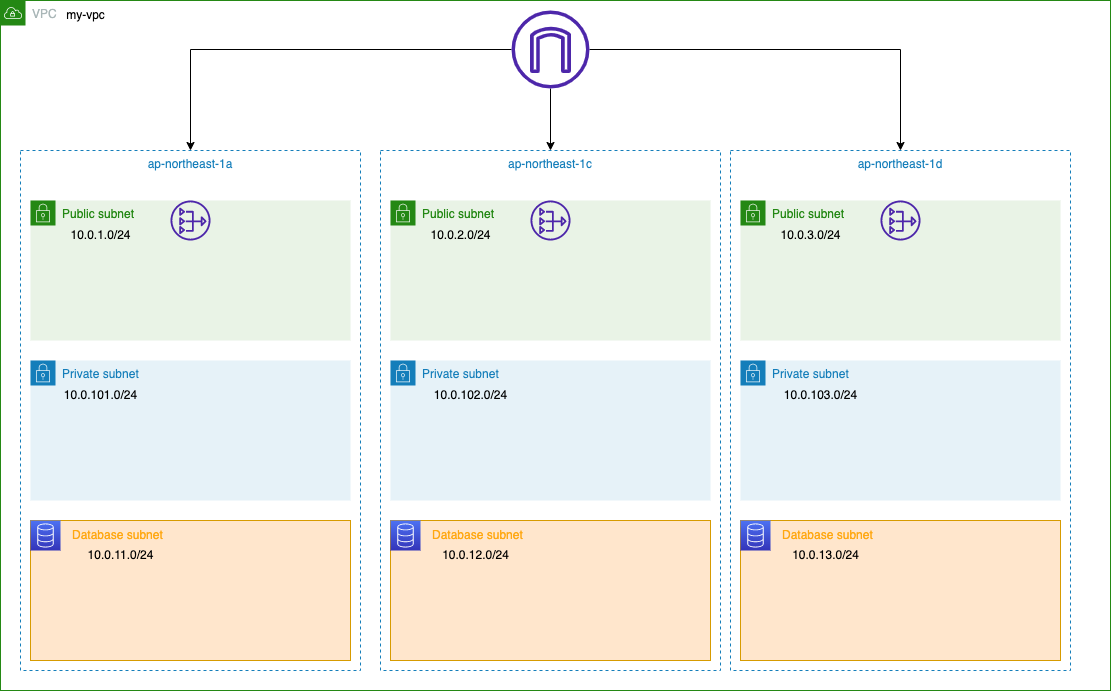
アーキテクチャ図

ファイル同期間にフォーカスをあてたアーキテクチャ図になります。Googleドライブのファイルが更新されたらS3にファイル同期を開始することも検討しましたが、認証周りの設定が面倒かつそこまでリアルタイムでの同期を求めていないということでしたので、毎日朝8時にFargateが起動してRcloneコンテナを実行しGoogleドライブからS3へファイルを同期するという手段を採用しました。
実装方法
Rclone設定
GoogleドライブとS3のRclone設定につきましてはクラスメソッドさんに詳しい手順がありますのでこちらを御覧ください。
一点考慮することとしてS3の設定でRcloneの設定ファイルにIAMユーザーのアクセスキーとシークレットキーをハードコーディングする箇所がありますが、Fargate上で実行する場合IAMロールをアタッチしてS3へファイル同期する権限を渡しますのでここの設定は不要となります。その他は同じ設定で問題ありません。
- S3のRclone設定
#IAMロールで権限を設定するため「2」を選択
Option env_auth.
Get AWS credentials from runtime (environment variables or EC2/ECS meta data if no env vars).
Only applies if access_key_id and secret_access_key is blank.
Choose a number from below, or type in your own boolean value (true or false).
Press Enter for the default (false).
1 / Enter AWS credentials in the next step.
\ (false)
2 / Get AWS credentials from the environment (env vars or IAM).
\ (true)
env_auth> 2
GoogleドライブとS3のrclone configが完了したら~/.config/rclone/rclone.confに以下の設定が記載されます。
[google-drive]
type = drive
scope = drive
token = {アクセストークン情報}
team_drive =
root_folder_id =
[s3]
type = s3
provider = AWS
env_auth = true
region = ap-northeast-1
location_constraint = ap-northeast-1
acl = private
storage_class = STANDARD
このファイルをDockerfileと同じディレクトリにコピーしてRcloneの準備は完了です。
コンテナ設定
作成した設定ファイルをRcloneコンテナで動かすためのDockerfileを構築します。
FROM rclone/rclone COPY ./rclone.conf /config/rclone/rclone.conf CMD ["sync", "google-drive:<同期元Googleドライブフォルダ>", "s3:<同期先S3バケット/フォルダ>"] # 確認用 # CMD ["sync", "--dry-run", "google-drive:<同期元Googleドライブフォルダ>", "s3:<同期先S3バケット/フォルダ>"]
syncはrcloneのサブコマンドで同期元ストレージと同期先ストレージのファイル階層を同一にします。この時、同期先ストレージに既存ファイルやフォルダなどがある場合同期元ストレージとファイル階層をあわせるため削除されてしまいます。事前に--dry-runオプションをつけて動作確認することを推奨します。
Dockerfileの記載が完了しましたらコンテナイメージをビルドし、ECRへプッシュします。
- コンテナイメージpush手順
Fargate設定
次にタスク定義を作成します。FargateがS3へファイルを同期するための書き込み権限が必要になりますのでタスクロールに適切なIAMロールをアタッチします。

その他に特別な設定は不要でECRのコンテナイメージURIを指定しましたらデフォルトの設定で問題ありません。

EventBridgeScheduler設定
EventBridge Schedulerは2022年に発表されたEventBridgeの機能です。今回の要件でしたら従来のEventBridge ルール2でも実現できますので好みで選んでも問題ありません。
スケジュールステップで毎日朝8時にEventBridge Schedulerが起動できるように設定します。

ターゲット選択ステップでは先ほど作成したタスクを起動するRunTaskを選択し、実行対象ECSクラスターを決め次のステップに移ります。

設定ステップではEventBridge Scheduler自身がFargateタスクを起動できるようにするための新規IAMロールを作成する必要があります。設定ステップ内で新規IAMロール作成を選択した状態で次のステップに移動します。

確認ステップまで進み設定に問題がなければEventBridge Schedulerを作成します。
所感
最終的に毎朝8時にEventBridge SchedulerがECS Fargateタスクを起動し、GoogleドライブからS3へファイルを同期する上記アーキテクチャが完成しました。
デフォルト設定のままでしたらCloudWatch Logsに実行ログが記録されていますので毎朝の実行結果が確認できます。

弊社はログ運用をDatadogに寄せているのでしばらく動かして問題なさそうでしたらFargateコンテナのログをDatadogに転送しようかなと考えています。